
Today was a big day in the industry, to say the least. With the release of DeepSeek-R1 last week, stocks of the companies that are involved in the huge AI infrastructure build-out fell rapidly today as folks pondered the implications. Some folks say that the AI race is over, given a new lower-cost model is out. I think that is quite a bit overblown.
DeepSeek Day in AI
For those who did not see, today DeepSeek-R1 was released with some very impressive benchmark claims in terms of its accuracy:
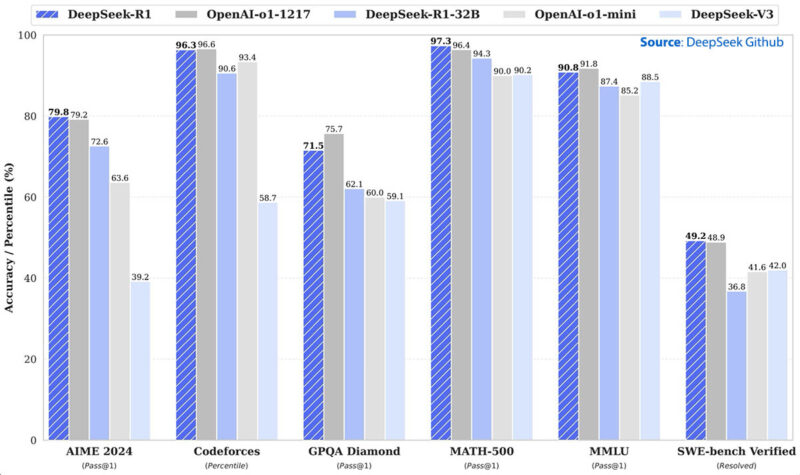
One impact of DeepSeek is that it is a competitive model. The more impressive bit might be the inputs to get that level of accuracy. In the DeepSeek-V3 paper, the company outlined a lot of its work to maximize the use of the NVIDIA H800 GPUs as well as limiting the inter-GPU communication. The NVIDIA H800 is a Hopper GPU designed to meet certain US export restrictions with one of the big differences being the GPU bandwidth. DeepSeek-V3 took something like 2.8M NVIDIA H800 hours. At $2/ hour that is under $6M of training time. DeepSeek-R1 costs more, but it is clear that the team’s innovations are yielding big benefits even just with FP8 training as an example.
As a result, a lot of folks are spooked today that this means the end to the AI infrastructure build-out, or at least a significant slowing. I have a very different take on this. A NVIDIA HGX H200 8-GPU baseboard costs roughly $250K, with the entire system cost being $350K+.

As we went into this weekend in our Substack, the AMD Instinct MI325X and MI300X are designed to fit in the same form factor, but there is a big difference on the board itself. Whereas the NVIDIA GPUs are designed with a NVLink switch architecture on the HGX H200 8-GPU platform, the AMD Instinct UBB does not have the switched architecture helping to lower costs. Part of what DeepSeek outlined in its V3 paper is that it had to minimize the inter-GPU communication so we see that as part of the team’s “secret sauce.” Its engineering insights will be adopted by the broader community and hopefully that makes both training, and more importantly, inference more accessible to other architectures.

Lowering the costs of the compute, and potentially working around architectural limitations is how AI applications will proliferate. Today, folks are still very focused on LLMs that look like text prompts. The next steps are making machines integrate with humans and then with each other. Some of the coolest demos I get to see for AI applications are those that do not look like chatbots. About a year ago I saw one that was quite mind-blowing. I asked how much it cost to operate, and the company was saying that a single HGX H100 8-GPU machine could do the work of two people. In many places, a system that will have a 3-year cost of $500K that can do the work of two people is not exciting. Frankly, even at 1/5th of that, it is not enough. At 1/50th or 1/100th of the cost, the demo would be revolutionary.
At some point, scaling needs to come both from hardware, but also from model engineering optimization. When we start getting more performance from the hardware, and large jumps from new techniques and optimizations, that is when the costs come down dramatically. For the past year, I have had a demo that I use as a reference. At 1/100th the cost, this demo is something that would be widely adopted. Whenever I see a company making big gains on hardare or techniques, that is all I can think about.
Final Words
Perhaps the other side that spooked people today is that the prevailing theme has been building larger GPU clusters and having more compute would determine the winner. Today’s DeepSeek-R1 release does not fit that narrative. Another way to say that is that DeepSeek’s results seem to indicate that it is not just which organization can amass the largest compute infrastructure.
To me, the training side has been fun, as we have been covering systems for training for a decade. Still, the much bigger application will be inferencing since that is how these models will be deployed and become useful. We will, of course, still show the big training machines, but I really want to show the next step in how these models will be deployed.



{kind=link}